EdgeBoard 中CNN架构的剖析
2020-03-28 01:30:31来源:民营经济网·民企动力
人工智能领域边缘侧的应用场景多种多样,在功能、性能、功耗、成本等方面存在差异化的需求,因此一款优秀的人工智能边缘计算平台,应当具备灵活快速适配全场景的能力,能够在安防、医疗、教育、零售等多维度行业应用中实现快速部署。
百度大脑EdgeBoard嵌入式AI解决方案,以其丰富的硬件产品矩阵、自研的多并发高性能通用CNN(Convolution Neural Network)设计架构、灵活多样的软核算力配置,搭配移动端轻量级Paddle Lite高效预测框架,通过百度自定义的MODA (Model Driven Architecture)工具链,依据各应用场景定制化的模型和算法特点,向用户提供高性价比的软硬一体的解决方案,同时和百度大脑模型开发平台(AIStudio、EasyDL)深度打通,实现模型的训练、部署、推理等一站式服务。
1. EdgeBoard计算平台的多产品矩阵
EdgeBoard是基于Xilinx 16nm工艺Zynq UltraScale+ MPSoC的嵌入式AI解决方案,采用Xilinx异构多核平台将四核ARM Cortex-A53处理器和FPGA可编程逻辑集成在一颗芯片上,高性能计算板卡上搭载了丰富的外部接口和设备,具有开发板、边缘计算盒、抓拍机、小型服务器、定制化解决方案等表现形态。
EdgeBoard计算卡产品可以分为FZ9、FZ5、FZ3三个系列,是基于Xilinx XCZU9EG、XAZU5EV、XAZU3EG研发而来,分别具有高性能,视频硬解码,低成本等特点,同时还有不同的DDR容量版本。以上三个版本PS侧同样采用四核Cortex-A53 、双核Cortex-R5、以及GPU Mali-400MP2等处理器配置,PS到PL的接口均为12x32/64/128b AXI Ports,主要的区别在于PL侧拥有的芯片逻辑资源大小不同,可参见下表。
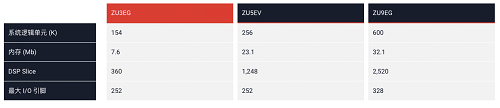
采用上述三种标准产品的硬件板卡或者一致的硬件参考设计,用户可无缝适配运行EdgeBoard公开发布的最新版标准镜像,也可根据自身项目需求定制相关的硬件设计,并进一步根据性能、成本和功耗要求,以及其他功能模块的集成需求,对软核的算力和资源进行个性化配置。(多款开发板适配视频教程:https://ai.baidu.com/forum/topic/show/957750)
2. 高性能的通用CNN设计架构
2.1 CNN加速软核的整体设计框架
EdgeBoard的CNN加速软核(整体的加速方案称之为软核)提供了一套计算资源和性能优化的AI软件栈,由上至下分别包括应用层软件API、计算加速单元的SDK调度管理、Paddle Lite预测框架基础管理器、Linux操作系统、负责设备管理和内存分配的驱动层和CNN算子的专用硬件加速单元,用来完成卷积神经网络模型的加载、解析、优化和执行等功能。
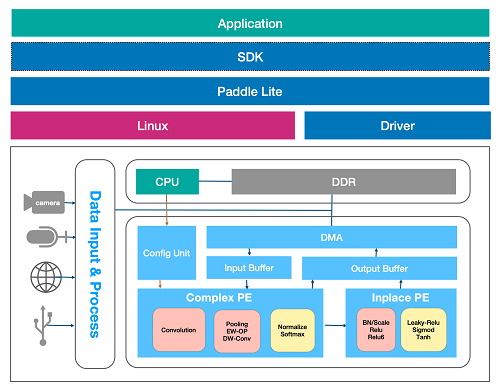
这些主要组成部分在软件栈中功能和作用相互依赖,承载着数据流、计算流和控制流。基于上图设计框架,EdgeBoard的AI软件栈主要分为4个层次:
Ø 应用使能层
面向用户的应用级(APP)封装,主要是面向计算机视觉领域提供图像处理和神经网络推理的业务执行API。
Ø 执行框架层
Paddle Lite预测框架提供了神经网络的执行能力,支持模型的加载、卸载、解析和推理计算执行。
Ø 调度使能层
SDK调度使能单元负责给硬件派发算子层面的任务,完成算子相应任务的调度、管理和分发后,具体计算任务的执行由计算资源层启动。
Ø 计算资源层
专用计算加速单元搭配操作系统和驱动,作为CNN软核的计算资源层,主要承载着部分CNN算子的高密度矩阵计算,可以看作是Edgeboard的硬件算力基础。
2.2 CNN算子的加速分类
专用计算加速单元基于FPGA的可编程逻辑资源开发实现,采用ARM CPU和FPGA共享内存的方式,通过高带宽DMA(Direct Memory Access)实现二者数据的高速交互,共享内存也并作为异构计算平台各算子数据在CPU和FPGA协同处理的桥梁,减少了数据在CPU与FPGA之间的重复传输。此外,CNN算子功能模块可直接发起DDR读写操作,充分发挥了FPGA的实时响应特性,减少了CPU中断等待的时间消耗。
根据CNN算子的计算特点,EdgeBoard的算子加速单元可划分为如下两类:
Ø 复杂算子加速单元
顾名思义,是指矩阵计算规则较为复杂,处理数据量较多,由于片上存储资源限制,通常需要多次读写DDR并进行分批处理的算子加速单元。
(1) 卷积(Convolution):包含常规卷积、空洞卷积、分组卷积、转置卷积,此外全连接(Full Connection)也可通过调用卷积算子实现。
(2) 池化(Pooling):包含Max和Average两种池化方式。
(3) 深度分离卷积(Depth-wise Convolution):与Pooling的处理特点类似,因此复用同样的硬件加速单元,提高资源利用率。
(4) 矩阵元素点操作(Element-wise OP):可转换为特定参数的Pooling操作,因此复用同样的硬件加速单元,提高资源利用率。
(5) 归一化函数(L2-Normalize):拥有较高处理精度,且实现资源最优设计。
(6) 复杂激活函数(Softmax):与Normalize处理特点相似,复用同样的硬件加速单元和处理流程,提高资源利用率。
Ø 通路算子加速单元
通路算子是指在复杂算子加速单元的计算数据写回DDR的流水路径上实现的算子,适合一些无需专门存储中间结果,可快速计算并流出数据的简单算子。
(1) 各类简单激活函数(Relu, Relu6, Leaky-Relu, Sigmoid, Tanh):基本涵盖了CNN网络中常见的激活函数类型。
(2) 归一化(Batch norm/Scale):通常用于卷积算子后的流水处理,也可支持跟随在其他算子后的流水处理。
另外一种分类方式,是根据CNN网络里的算子常用程度划分为必配算子和选配算子,前者指CNN软核必需的算子单元,通常对应大部分网络都涉及的算子,或者是芯片资源消耗极少的算子;后者指CNN软核可以选择性配置的算子单元,通常是特定的网络会有的特定算子。这样划分的好处是,用户根据MODA工具链自定义选择,减少了模型中无用算子造成的逻辑资源的开销和和功耗的增加。
Ø 必配算子:Convolution, Pooling, Element-Wise, Depth-Wise Convolution, BN/Scale, Relu, Relu6
Ø 选配算子:Normalize, Softmax, Leaky-Relu, Sigmoid, Tanh
2.3 卷积计算加速单元的设计思路
作为CNN网络中比重最大、最为核心的卷积计算加速单元,是CNN软核性能加速的关键,也占用了FPGA芯片的大部分算力分配和逻辑资源消耗。下面将针对EdgeBoard卷积计算加速单元的设计思路进行简要介绍,此章节也是理解CNN软核算力弹性配置的技术基础。
每一层网络的卷积运算,有M个输入图片(称之为feature map,对应着一个输入通道),N个输出feature map(N个输出通道),M个输入会分别进行卷积运算然后求和,获得一幅输出map。那么需要的卷积核数量就是M*N。
针对上述计算特点,EdgeBoard的卷积单元采用脉动阵列的数据流动结构,将数据在PE之间通过寄存器进行打拍操作,可以实现在第二个PE计算结果出来的同时完成和前一个PE的求和。这样可以使数据在运算单元的阵列中进行流动,减少访存的次数,并且结构更加规整,布线更加统一,提高系统工作频率,避免了采用加法树等并行结构所造成的高扇出问题。
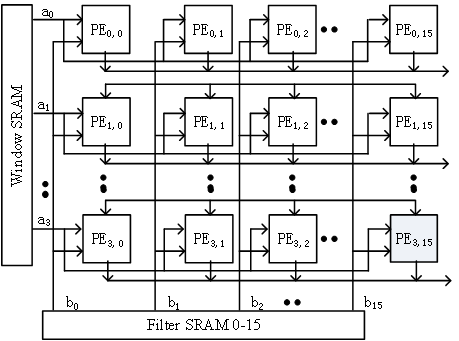
因此,如上图所示,我们可以分别从Feature Map和Kernel两个维度去定义脉动阵列的并行结构。从Feature Map的角度,纵向的行与行直接卷积窗口相互独立,也就是输出的每行之间所对应的数据计算互不干扰,在此维度定义的多并发计算称之为Window维度的并行度。从Kernel的角度,为了达到计算结果的快速流出减少片上缓存占用,我们设计了每个Kernel核之间的多并发计算,称之为Kernel维度的并行度。以上两个维度同时并发既可以提高整体并行计算效率,也充分利用了脉动阵列的数据流水特性。
2.4 卷积计算加速单元的通用性扩展
前一章节详细介绍了基于PL实现的卷积计算加速单元的设计原理,那么如果是由于芯片的SRAM存储资源不够而导致的CNN网络参数支持范围较小,EdgeBoard将如何拓展CNN软核的网络支持通用性? 我们可以利用灵活的SDK调度管理单元提前将Feature Map或者Kernel数据进行拆分,然后再执行算子任务的下发。
Ø 一条滑窗链的Feature Map数据不够存储
SDK可以将一条滑窗链的Feature Map数据分成B块,并将分块数B和每个块的数据量告诉卷积计算加速单元,那么后者则可以分批依次从DDR读取B次Feature Map数据,每次的数据量是可以存入到Image SRAM内。
Ø Kernel的总体数据不够存储
SDK可以将Kernel的数量分割成S份,使得分割后的每份Kernel数量可以下发到PL侧的Filter SRAM中,然后SDK分别调度S次卷积算子执行操作,所有的数据返回DDR后,再从通道(Channel)维度做这S次计算结果的数据拼接(Concat)即可。不过要注意的是,我们的Filter SRAM虽然不需存储所有Kernel的数据量,但至少要保证能够存储一个Kernel的数据量。
由此看来,即使EdgeBoard三兄弟中最小的FZ3拥有极其有限的片上存储资源,也是能够很好地完成大多数CNN网络的参数适配。
3.软核算力的弹性配置
Edgeboard的CNN软核除了公开发布的标准版本外,还可以由用户根据自身模型需求和FPGA芯片选型,进行CNN卷积计算单元算力的定制化配置。配置算力的两个关键指标包括Window维度并行度和Kernel维度并行度,具体含义可参考2.3章节,此处不再赘述。
我们以卷积计算加速单元的核心矩阵乘加运算消耗DSP硬核(Hard core)的个数作为CNN软核核心算力的考察指标。当然,这并不包括卷积前处理、后处理模块,以及其他算子加速单元或者用户自定义功能模块所消耗的DSP数量,因此这并不是整个解决方案在FPGA芯片内部的DSP资源消耗。我们的设计可以支持Window并行度1-8的任意整数,支持Kernel并行度包括4,8,16。具体的卷积双维度配置组合所对应的核心DSP消耗可以参见下表。
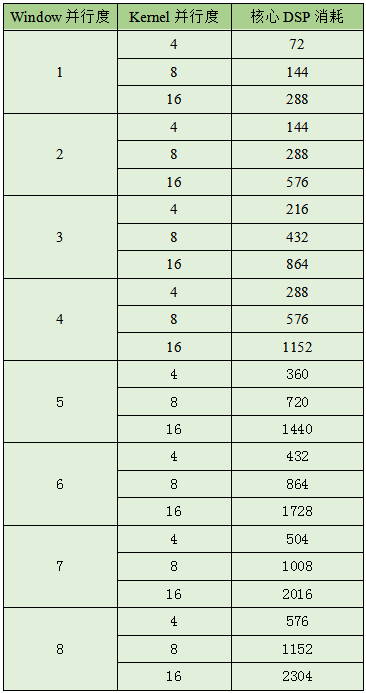
目前,EdgeBoard公开版针对卷积计算加速单元Window维度和Kernel维度的并行度配置,以及核心矩阵乘加运算的DSP硬核消耗可参见下表。

EdgeBoard的CNN软核以其灵活的算力搭配组合以及算子可定制化的特点,既可以根据具体模型的算子组合和所占比例,将一定成本和资源条件内的芯片性能发挥到极致,还可以在满足场景所要求性能的前提下减少不必要的功耗支出,此外还允许开发者缩减软核尺寸并将芯片资源应用于自定义功能的IP中,极大地增强了EdgeBoard人工智能多场景覆盖的能力。
责任编辑:张富强
免责声明:本文仅代表作者个人观点,与民营经济网无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
如有问题,请联系我们!





